Storm是分布式实时计算系统,它对应的是Hadoop的批处理,Storm处理的则是连续不断的数据流,它使用以下的场景:
流式数据,数据并不是静态的存在于某个存储设备,而是动态的数据流。
分布式的RPC,由于storm是分布式并且处理的延迟很低,通常可以作为RPC框架来使用。
持续计算,任务只用初始化一次,并且一直运行。
Storm架构
Storm和Hadoop一样,也采用了Master/Slave的模型,它有两种进程,一个是Nimbus和Supervisor。Nimbus运行在主节点,它的主要功能如下:
负责分发代码
负责给
Supervisor安排分配任务故障检测,即当
Supervisor出现故障时,及时的进行处理。
Supervisor运行在主节点,它的主要功能比较单一,就是执行具体的任务(Spout/Blot)
Supervisor和Nimbus不会直接的进行 交互,而是通过Zookeeper来协调,并且,所有的状态信息,心跳信息,配置信息等都保存在Zookeeper的znode中。所以,无论是Supervisor和Nimbus,都是快速失败的,瞬时的宕机和重启,对系统来说没有影响。
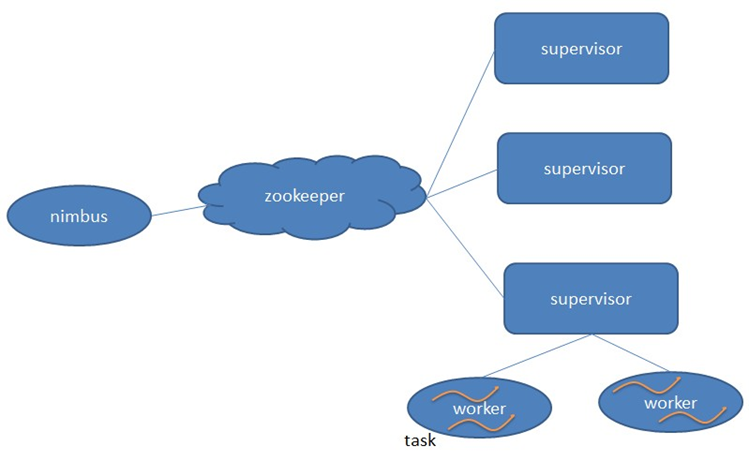
以上是从集群的角度来分析Storm的架构。下面将具体的分析Storm的具体元素
基本概念
为了实现分布式的实时计算系统,Storm定义了很多基本元素用于计算,例如:Topology, Stream, Spout, Bolt,Tuple, Stream Group等。
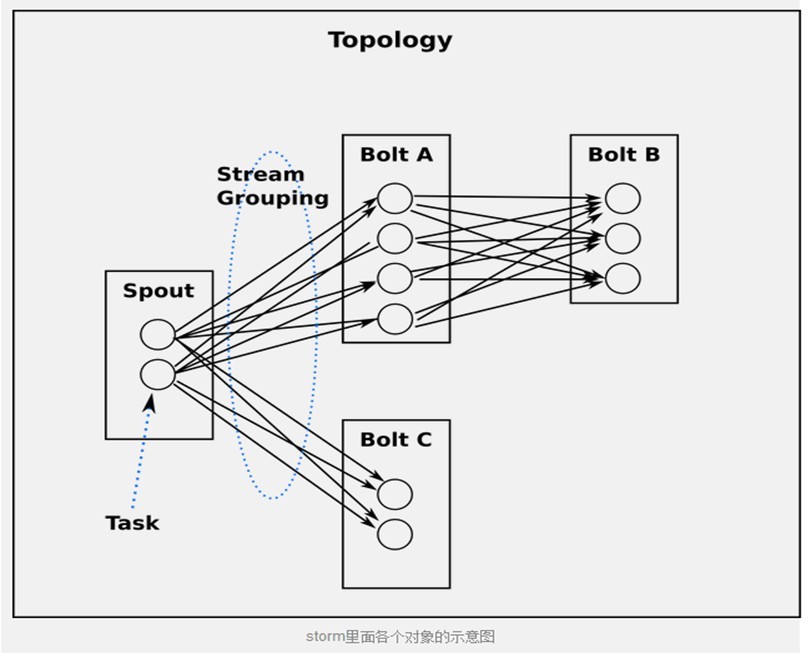
以上是Storm的一个topology模型图。
Topology
在Hadoop上运行的是一个Job,在tomcat里运行的是一个Web Application,而在Storm中,运行的是Topology. 它是一个整体的概念,而不是具体的对象,它包含了执行实时计算的基本元素,例如:Spout, Bolt,并且规定数据是怎么在这些组件里传输的。
Tuple
tuple是storm的主要数据结构,并且是storm中使用的最基本单元、数据模型和元组。tuple就是一个值列表,tuple中的值可以是任何类型的。它的官方定义如下:
“A tuple is a named of values where each value can be any type.” tuple是一个类似于列表的东西,存储的每个元素叫做field(字段),可以是任何类型

每个tuple是一堆值,每个值都有一个名字,一个Tuple代表数据流中的一个基本处理单元,例如:一条cookie日志,他可以包含多个Field, 每个Field表示一个属性。
定义一个Tuple:
declareOutputFields方法定义要输出的字段 : [“double”, “triple”]。
也可以使用自己创建的对象来作为值,但是必须实现序列化。
Stream
一个Stream是没有边界的Tuple序列,这些tuples会被以一种分布式的方式并行地创建和处理。每一个Stream在声明的时候都会赋予一个id。
Spouts
它是Topology中数据的源头。一般来说消息源会从一个外部源读取数据并且向topology里面发出消息: tuple。
Spout可以是可靠的,也可以是不可靠的,可靠的spout会在发送Tuple失败的情况下,重复发送;相反,不可靠的spout会忘记它发送过的Tuple,无论是否成功。
Spouts能够发送多个流:使用OutputFieldsDeclarer(interface)的declareStream方法声明多个流,并且当使用SpoutOutputCollector(实现2,接口模式)的emit方法可以指定这个流去发送Tuple。
Spouts的主要方法:
nextTuple(), nextTuple可以发送一个新的Tuple到Topology,或者当没有新的Tuple被发送的时候,就简单的返回。对于任何spout的实现,nextTuple都不能阻塞,因为Storm调用的所有spout都是基于同一个线程!用户不能提供一个阻塞式的实现,否则可能阻塞整个后台循环。另外,后台可能会调节nextTuple()的调用频率,比如系统有一个配置参数可以控制当前被pending的Tuple最大数目,如果达到这个限制,可能就会做一些流控。
ack和fail则是两个回调函数。Spout在发射出一个tuple后,该tuple会通过acking机制被acker追踪,除了显式的fail和ack外,每个tuple有一个超时时间,如果超过这个时间还未确定该tuple的状态,那么acker会通知spout,这个tuple处理失败了,然后框架得到这个消息后,就会调用spout的fail函数,如果acker发现这个tuple处理成功了,也会通知spout,然后会调用spout的ack函数。所以通常来说用户在发射tuple时,要确保数据不丢失,都会将已经发射的tuple缓存起来,然后在ack函数中删除对应tuple,在fail函数中重发对应的tuple。
Spouts使用SpoutOutputCollector来发送tuple的:
Spout通过调用ISpoutOutputCollector的emit函数进行tuple的发射,但实际上,emit函数也没有真正的去发送,它主要是根据用户提供的streamId,计算出该tuple需要发送到的目标taskID;emitDirect函数,更裸一些,直接指定目标taskID。它们都只是将
Bolt
消息是如何处理的,被封装在bolt中,不同的bolt,可以实现不同的逻辑,过滤,聚合,查询数据库等等等等。复杂的消息流处理往往需要很多步骤,比如算出一堆图片里面被转发最多的图片就至少需要两步: 第一步算出每个图片的转发数量。第二步找出转发最多的前10个图片。
Bolts可以发射多条消息流,使用OutputFieldsDeclarer.declareStream定义stream,使用OutputCollector.emit来选择要发射的stream。
excute方法,它以一个tuple作为输入,Bolts使用OutputCollector来发射tuple,Bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知storm这个tuple被处理完成了。– 从而我们通知这个tuple的发射者Spouts。
一般的流程是:Bolts处理一个输入tuple,发射0个或者多个tuple,然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack。
|
|
IOutputCollector是会被Bolt调用的,与ISpoutOutputCollector功能类似。但是区别也很明显,首先我们可以看到它的emit系列函数,多了一个参数Collection
除了anchors参数外,IOutputCollector还多了ack和fail两个接口。这两个接口,与Spout的ack和fail完全不同,对于Spout来说ack和fail是提供给Spout在tuple发送成功或失败时进行处理的一个机会。而IOutputCollector的ack和fail则是向acker汇报当前tuple的处理状态的,是需要Bolt在处理完tuple后主动调用的。
Stream groupings
定义一个Topology的其中一步是定义每个bolt接受什么样的流作为输入。stream grouping就是用来定义一个stream应该如果分配给Bolts上面的多个Tasks。
storm里面有6种类型的stream grouping:
Shuffle Grouping: 随机分组, 随机派发stream里面的tuple, 保证每个bolt接收到的tuple数目相同。
Fields Grouping:按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts, 而不同的userid则会被分配到不同的Bolts。
All Grouping: 广播发送, 对于每一个tuple, 所有的Bolts都会收到。
Global Grouping: 全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
Non Grouping: 不分组, 这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者举鼎由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来或者处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)
并行度
storm拓扑的并行度可以从以下4个维度进行设置:
- node(服务器):指一个storm集群中的supervisor服务器数量。
- worker(jvm进程):指整个拓扑中worker进程的总数量,这些数量会随机的平均分配到各个node。
- executor(线程):指某个spout或者bolt的总线程数量,这些线程会被随机平均的分配到各个worker。
- task(spout/bolt实例):task是spout和bolt的实例,它们的nextTuple()和execute()方法会被executors线程调用。除非明确指定,storm会给每个executor分配一个task。如果设置了多个task,即一个线程持有了多个spout/bolt实例. 注意:以上设置的都是总数量,这些数量会被平均分配到各自的宿主上,而不是设置每个宿主进行多少个进程/线程。
一个worker是一个jvm进程,它只属于一个 topology,一个worker可以起多个executors去跑某个topology。 一个executor会跑多个tasks(默认配置是一个executor一个task),但是一个executor只属于一个spout或者bolt。
并行度的动态调整 对storm拓扑的并行度进行调整有2种方法:
kill topo—>修改代码—>编译—>提交拓扑
动态调整
第1种方法太不方便了,有时候topo不能说kill就kill,另外,如果加几台机器,难道要把所有topo kill掉还要修改代码? 因此storm提供了动态调整的方法,动态调整有2种方法:
ui方式:进入某个topo的页面,点击rebalance即可,此时可以看到topo的状态是rebalancing。但此方法只是把进程、线程在各个机器上重新分配,即适用于增加机器,或者减少机器的情形,不能调整worker数量、executor数量等
cli方式:storm rebalance 举个例子
1storm rebalance toponame -n 7 -e filter-bolt=6 -e hdfs-bolt=8
将topo的worker数量设置为7,并将filter-bolt与hdfs-bolt的executor数量分别设置为6、8. 此时,查看topo的状态是rebalancing,调整完成后,可以看到3台机器中的worker数量分别为3、2、2